在處理資料集時,資料清理是不可或缺的步驟,刪除不需要的數據或特徵以確保數據的品質是常見的操作,本文將說明資料清理中有關刪除的操作方法,內容包含:
2.程式碼
import pandas as pd
import numpy as np
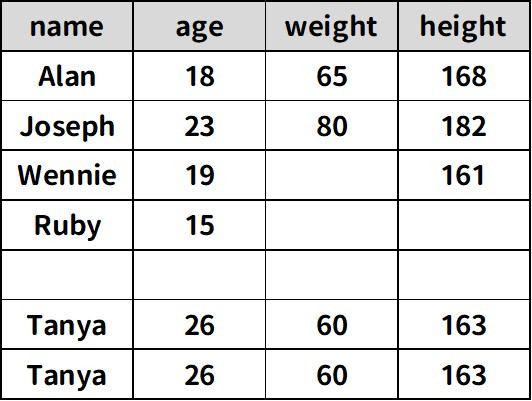
data = {'name':['Alan','Joseph','Wennie','Ruby',np.nan,'Tanya','Tanya'],
'age':[18,23,19,15,np.nan,26,26],
'weight':[65,80,np.nan,np.nan,np.nan,60,60],
'height':[168,182,161,np.nan,np.nan,163,163]}
df = pd.DataFrame(data)
Pandas 提供 dropna( how = 'any' 或 'all', subset = ['欄位名稱'] ) 方法刪除缺失值。
1. 刪除任一欄位有缺失值的資料
舉例:刪除案例中,有缺失值的 Wennie、Ruby 和 空白資料
print(df.dropna())
輸出結果:
2. 刪除全部欄位皆有缺失值的資料
舉例:刪除案例中整筆皆空白的資料
print(df.dropna(how='all'))
輸出結果:
3. 可接受缺失值,但刪除過多缺失的資料
當操作時可接受存在部分缺失值時,依照總欄位數量計算,採用參數 thresh 設定非缺失值(正確值)的最少數量。
舉例:案例資料共有四個欄位,最少須有三項數據無缺失,刪除不符合條件者(Ruby、空白)
print(df.dropna(thresh=3))
輸出結果:
4. 刪除特定欄位有缺失值的資料
舉例:刪除案例中 height 欄位有缺失的資料
print(df.dropna(subset=['height']))
輸出結果:
當資料集中出現一模一樣的重複資料時,可以使用 drop_duplicates( ) 進行刪除。
舉例:刪除案例中重複的 Tanya 資料,僅保留一筆
print(df.drop_duplicates())
輸出結果: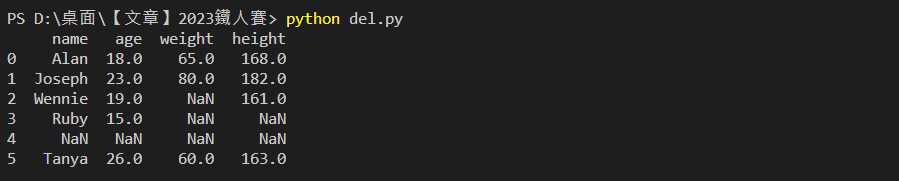
採用刪除的方式雖然非常快速,但也可能會導致分析出現誤差,需要多加考慮使用情況!如果有任何不理解、錯誤或其他方法想分享的話,歡迎留言給我!喜歡的話,也歡迎按讚訂閱!
我是 Eva,一位正在努力跨進資料科學領域的女子!我們下一篇文章見!Bye Bye~
【本篇文章將同步更新於個人的 Medium,期待與您的相遇!】


 iThome鐵人賽
iThome鐵人賽